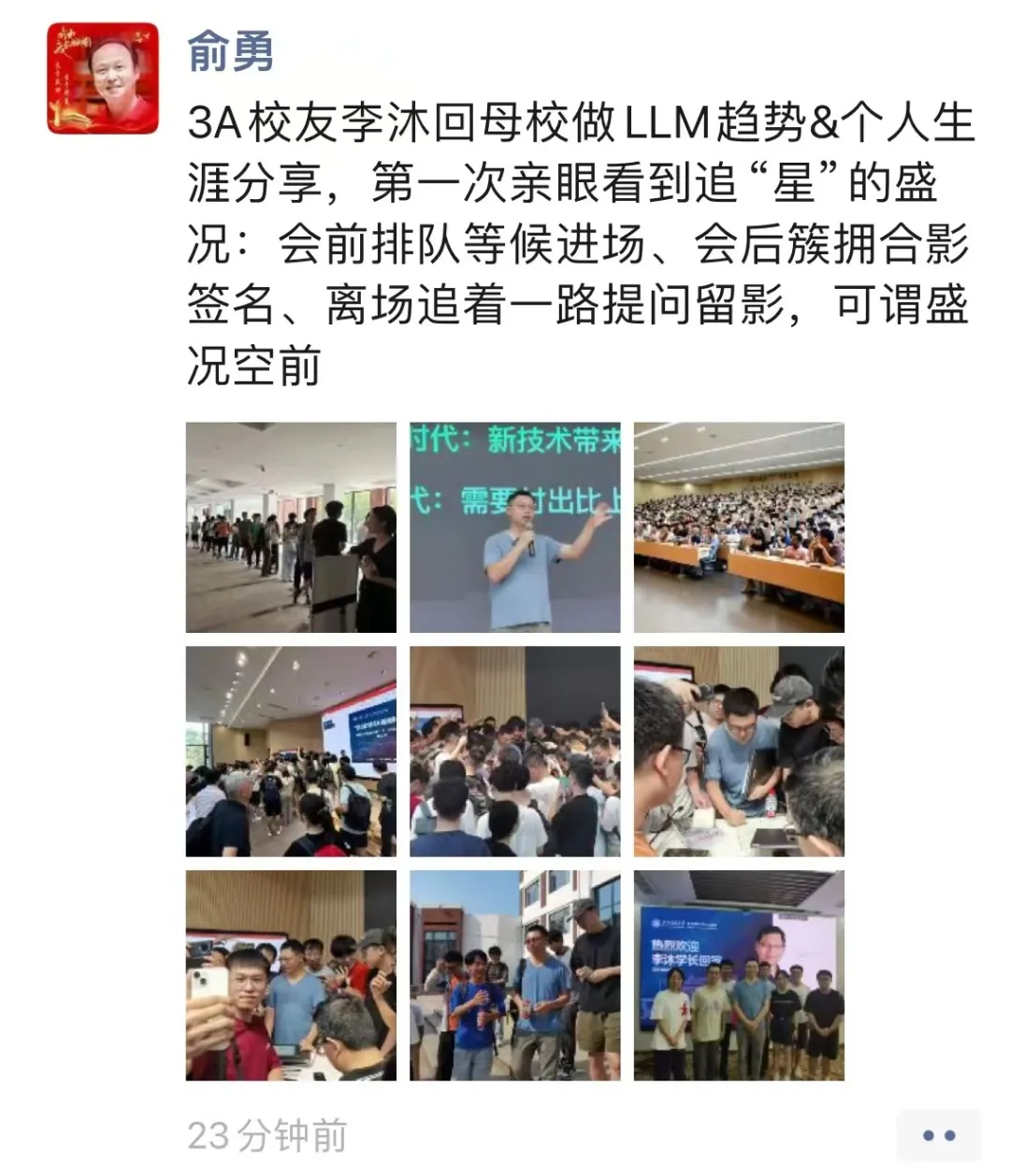
李沐重返母校上海交大,从LLM聊到个人生涯,这里是演讲全文
李沐重返母校上海交大,从LLM聊到个人生涯,这里是演讲全文昨天,李沐回到了母校上海交大,做了一场关于 LLM 和个人生涯的分享。本文是机器之心梳理的李沐演讲内容
来自主题: AI资讯
10752 点击 2024-08-25 11:15
 搜索
搜索
昨天,李沐回到了母校上海交大,做了一场关于 LLM 和个人生涯的分享。本文是机器之心梳理的李沐演讲内容
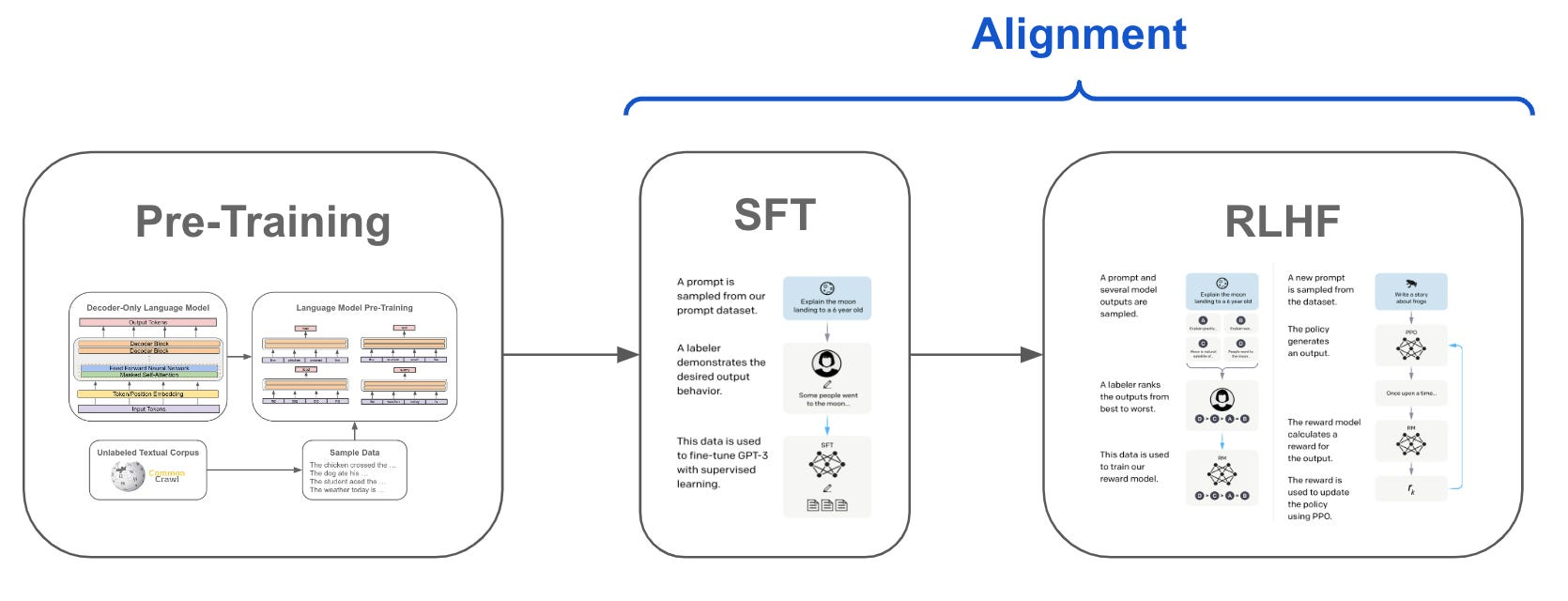
SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐

Replika 是一款虚拟陪伴(AI 伴侣)应用,成立于 2017 年,在 LLM 技术爆发之前。
检索增强生成(Retrieval-Augmented Generation, RAG)技术正在彻底革新 AI 应用领域,通过将外部知识库和 LLM 内部知识的无缝整合,大幅提升了 AI 系统的准确性和可靠性。然而,随着 RAG 系统在各行各业的广泛部署,其评估和优化面临着重大挑战

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。
随着大型语言模型(LLM)技术日渐成熟,各行各业加快了 LLM 应用落地的步伐。为了改进 LLM 的实际应用效果,业界做出了诸多努力。

地球是平的吗? 当然不是。自古希腊数学家毕达哥拉斯首次提出地圆说以来,现代科学技术已经证明了地球是圆形这一事实。 但是,你有没有想过,如果 AI 被误导性信息 “忽悠” 了,会发生什么? 来自清华、上海交大、斯坦福和南洋理工的研究人员在最新的论文中深入探索 LLMs 在虚假信息干扰情况下的表现,他们发现大语言模型在误导信息反复劝说下,非常自信地做出「地球是平的」这一判断。

从前两年的百模大战到大语言模型 LLM(Large Language Model)的逐步落地应用,端侧AI始终是人工智能技术发展中至关重要的一环。 所谓的端侧AI,即用户在使用过程中不依赖云服务器,直接在终端设备本地使用AI服务。相比于ChatGPT4.0和最新推出的Llama3.1等依赖于云端接口的主流大语言模型,设备端边缘应用的紧凑模型有较强的私密性,也具有个性化操作和节省成本等诸多优势。
为了对齐 LLM,各路研究者妙招连连。

大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。